
The Google File System: Large-Scale Distributed Storage
As the scale in big data continues to grow, companies like Google faced challenges in storing and managing massive amounts of data across thousands of commodity machines. The paper’s insights continue to influence distributed storage systems today.
The paper explains the logic behind the architecture assuming:
- Component failures are the norm, not the exception
- Files are huge by traditional standards
- Most files are mutated by appending, not overwriting
- Co-designing applications and API provides flexibility
The Architecture
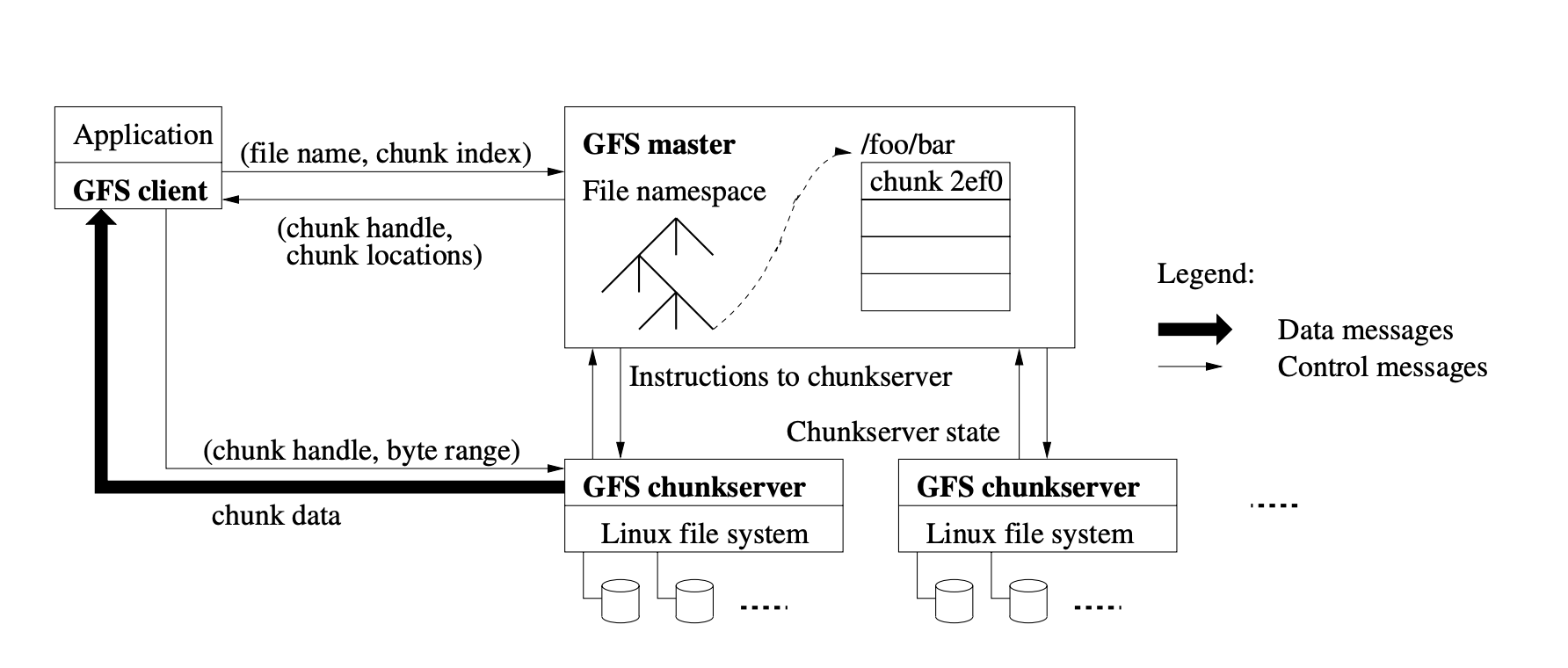
Master-Worker Design
GFS introduced a remarkably simple yet effective architecture:
- Single Master
- Maintains all metadata
- Handles system-wide coordination
- Makes all placement decisions
- Typically 64 bytes of metadata per file
- Multiple Chunkservers
- Store actual file data in chunks (64MB)
- Replicate chunks for reliability
- Report status to master via regular HeartBeat messages
Key Innovations
1. Chunk-Based Storage
The 64MB chunk size was much larger than typical block sizes in traditional file systems. This brought several advantages:
- Reduced master workload
- Fewer network connections
- Reduced metadata overhead
2. Relaxed Consistency Model
GFS made a choice with its consistency guarantees:
- Strong consistency for metadata operations
- Relaxed consistency for data mutations
- Atomic append operation for concurrent writers
This model matched real-world application needs while simplifying the system design.
Technical Deep Dive
Metadata Management
The master stores three major types of metadata:
- File and chunk namespaces
- Mapping from files to chunks
- Locations of chunk replicas
All metadata fits in memory, with operation log persisted to disk and replicated.
Chunk Management
GFS handles chunks through several sophisticated mechanisms:
- Creation
- Master picks location based on:
- Available disk space
- Load distribution
- Failure domains
- Master picks location based on:
- Replication
- Maintains 3 replicas by default
- Uses chain replication for efficiency
- Prioritizes replica placement across racks
- Re-replication
- Triggered by:
- Chunkserver failures
- Disk corruption
- Replication factor falling below threshold
- Triggered by:
Failure Handling
The paper describes robust mechanisms for handling various failures:
- Master Failures
- Operation log and checkpoints enable quick recovery
- Shadow masters provide read-only access during outages
- Chunkserver Failures
- Regular health monitoring
- Automatic re-replication
- Client-side failover
Real-World Impact
GFS’s influence extends far beyond Google:
- Open Source Implementation
- Hadoop Distributed File System (HDFS) was directly inspired by GFS
- Powers much of the big data ecosystem
- HDFS however differs with GFS in that it has a secondary master node, which takes snapshots of the master node
- Design Patterns
- Single master architecture with distributed workers
- Separation of metadata and data paths
- Chunk-based storage model