
Understanding Kubernetes Scheduling: Code Walkthrough
Run()
In the Run() function, the following code is executed:
1
go wait.UntilWithContext(ctx, sched.ScheduleOne, 0)
- The function blocks until the context is canceled.
- The comment explains that the ScheduleOne function is run in a
separate goroutinebecause it is blocking (i.e., it waits until the next item is available from the SchedulingQueue). - If this blocking code were run in the same goroutine as the main
Runfunction, it could prevent theSchedulingQueuefrom shutting down properly, resulting in a deadlock, where the program would freeze and be unable to proceed or shut down. wait.UntilWithContext(ctx, sched.ScheduleOne, 0): This function call runssched.ScheduleOnerepeatedly in the new goroutine. It continues runningsched.ScheduleOneuntil the provided context ctx is canceled. The second parameter 0 likely means there is no delay between consecutive calls.
After scheduling, the context waits for a signal to close the scheduling queue:
1
2
<-ctx.Done()
sched.SchedulingQueue.Close()
The SchedulingQueue is closed when the context is done.
Types of Queues
- Active Queue: This queue contains pods that are scheduled.
- Backoff Queue: This queue holds pods that have failed to schedule. These queues are implemented using a PriorityQueue.
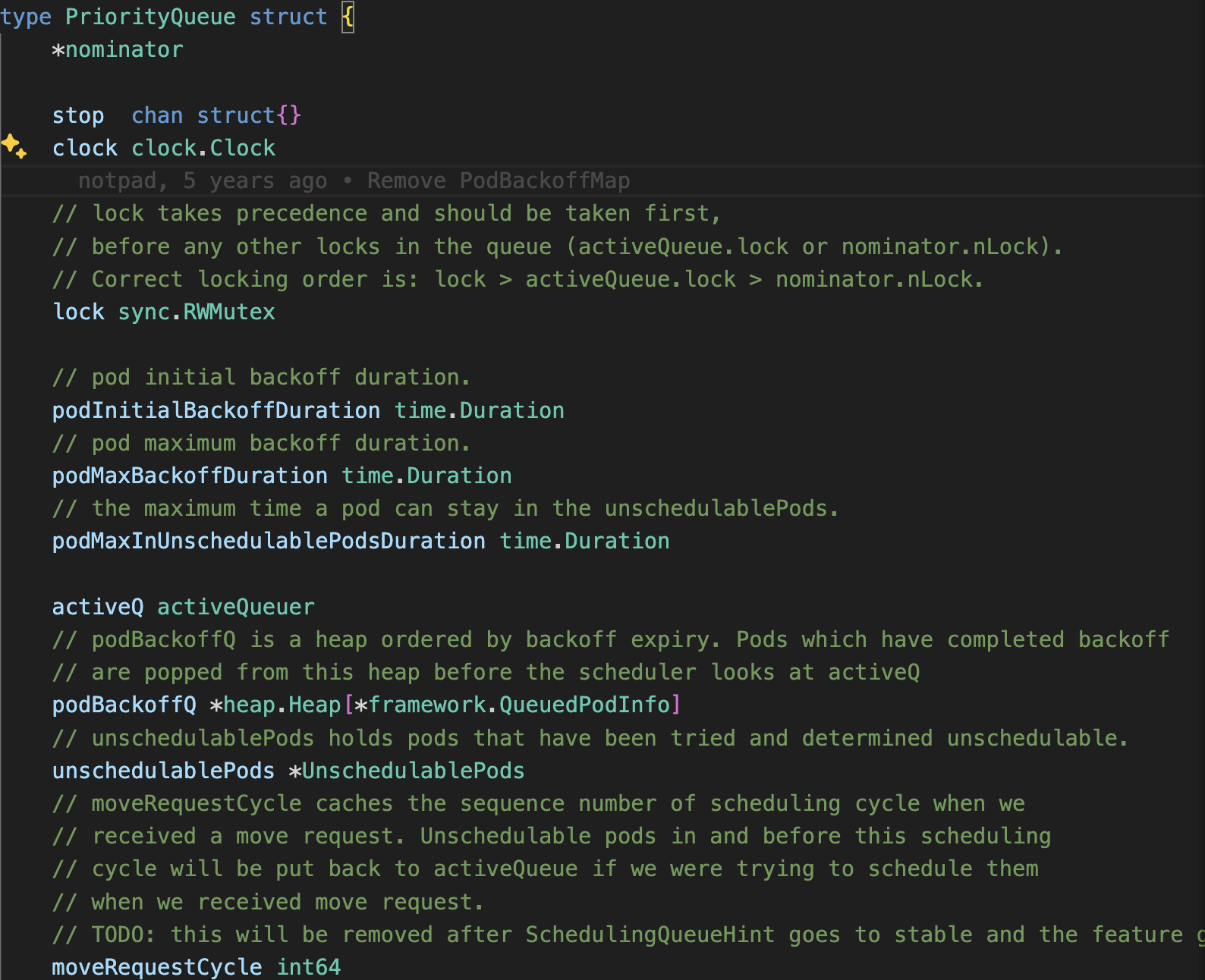 If you take a notice at how the Priority Queue is actually implemented, internally, it uses a heap.
If you take a notice at how the Priority Queue is actually implemented, internally, it uses a heap.
- some notable field is
Unschedulable Pods: Some pods cannot be scheduled at all.
scheduleOne
Within the scheduleOne function, pod scoring is managed through the schedulingCycle.
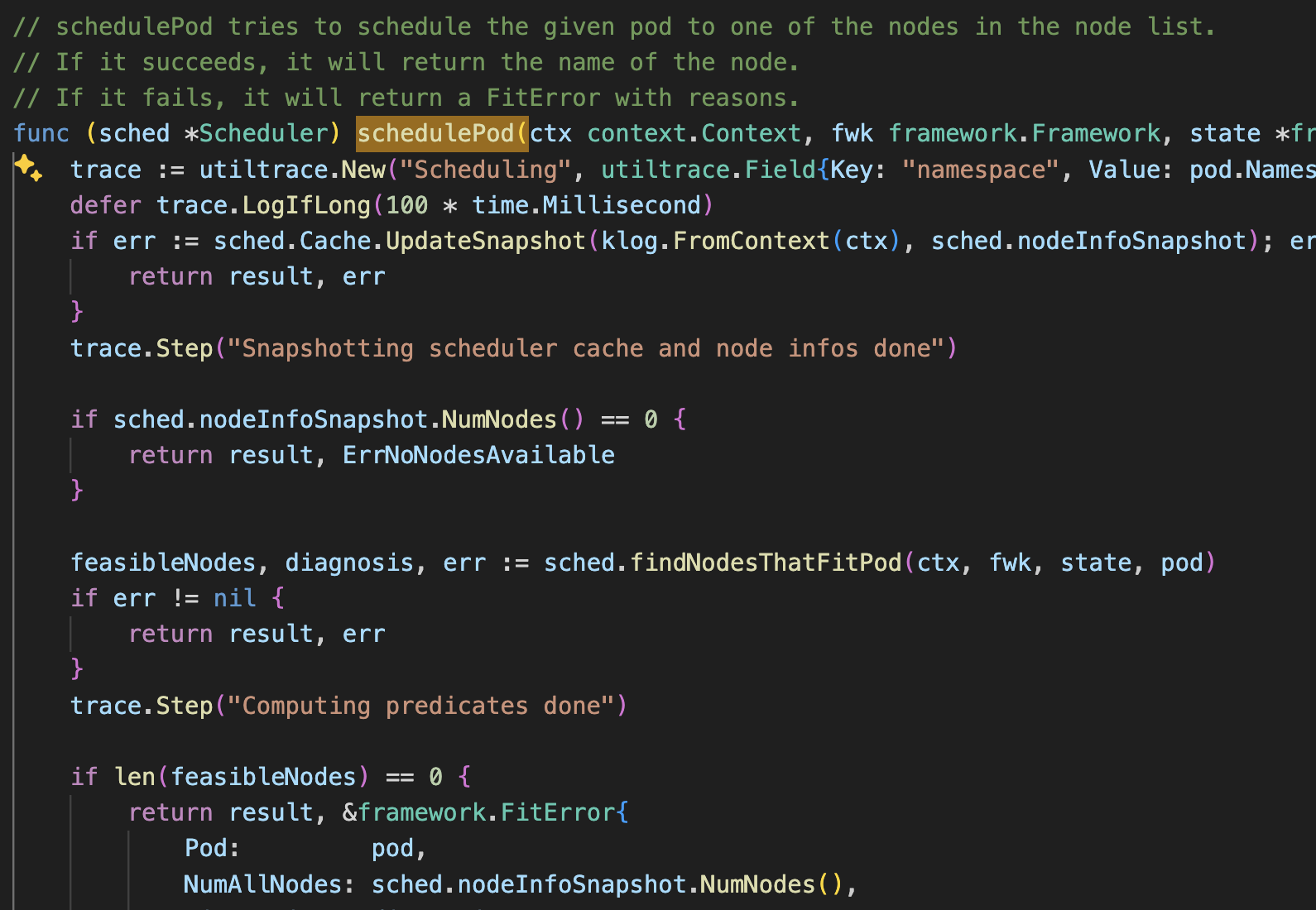
Logic Breakdown
- findNodesThatFitPod
If a pod is UnschedulableAndUnresolvable, it cannot be forcibly assigned to a node via preemption, leading to the suspension of the scheduling cycle. For pods that are currently unschedulable but might be schedulable later, other filters are checked.
1
2
3
4
5
6
checkNode := func(i int) {
// We check the nodes starting from where we left off in the previous scheduling cycle,
// ensuring all nodes have an equal chance of being examined across pods.
nodeInfo := nodes[(sched.nextStartNodeIndex+i)%numAllNodes]
status := fwk.RunFilterPluginsWithNominatedPods(ctx, state, pod, nodeInfo)
}
Nodes are examined starting from the last node checked in the previous scheduling cycle, ensuring a fair chance for all nodes.
Scoring Pods Pods are scored based on how well they fit the available nodes.
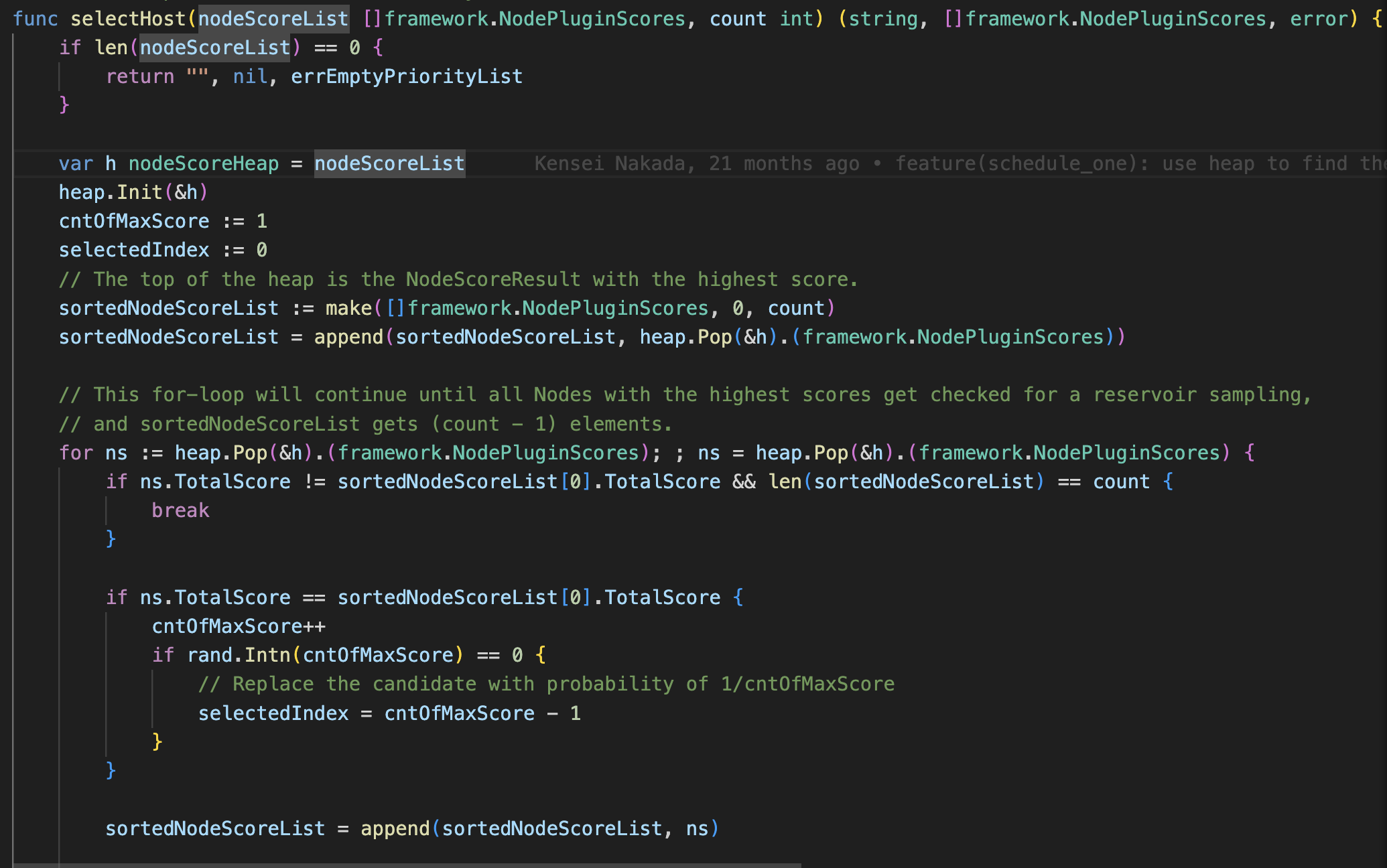
selectHost
![selectHost]() The selection process employs reservoir sampling, where the probability of the j-th node being chosen is 1/j.
The selection process employs reservoir sampling, where the probability of the j-th node being chosen is 1/j.
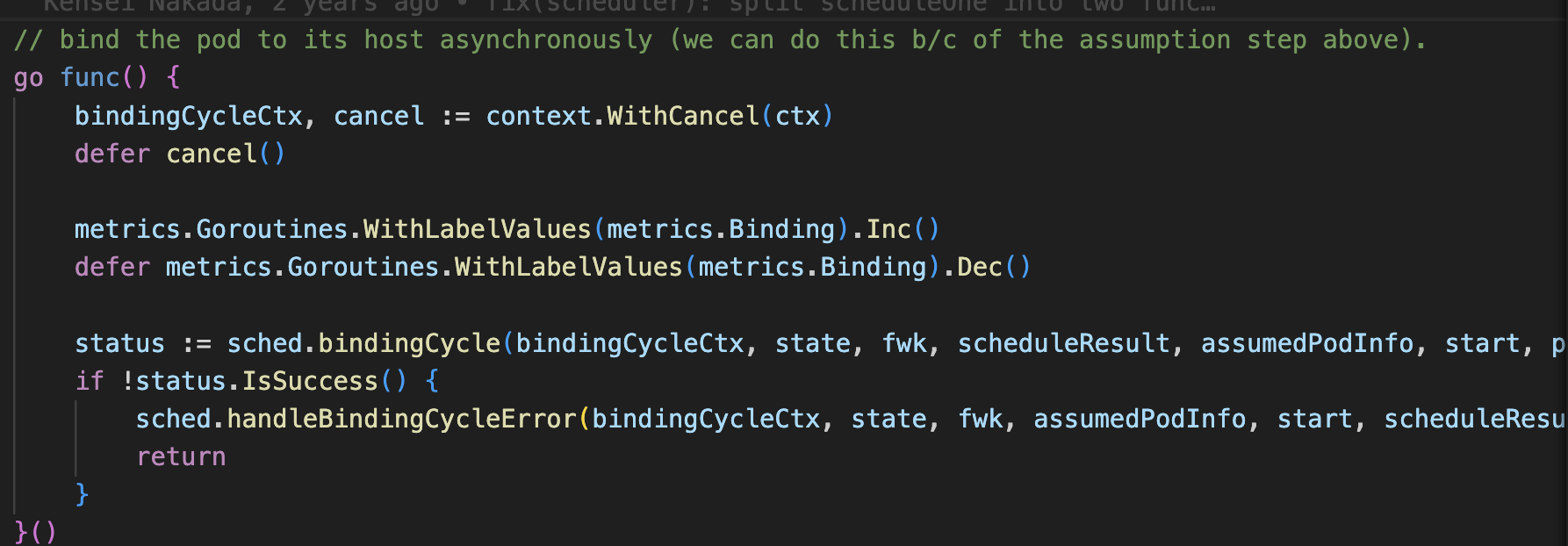
Binding
When a node is selected for scheduling, it is assumed to be bound, with actual binding occurring asynchronously in a goroutine.
Framework
The Framework interface manages the set of plugins utilized in Kubernetes scheduling, which include:
- Filter Plugin: Filters nodes based on specified criteria.
- Score Plugin: Assigns scores to nodes based on how well they fit the pods.
- Prefilter Plugin: Additional filtering before the main scheduling process.
- Bind Plugin: Handles the binding of pods to nodes.
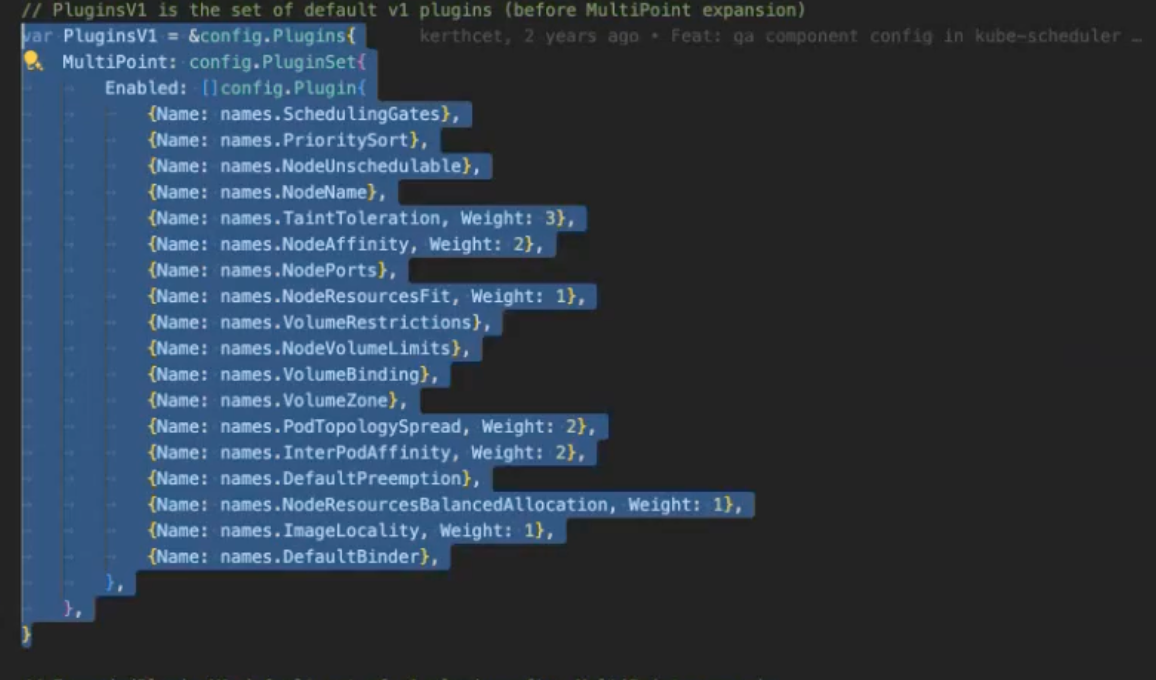
This is how the the filter plugins are instantiated. If no score plugin is defined, a simple round-robin approach is utilized for scheduling.