
MapReduce: The Paper That Revolutionized Big Data Processing
MapReduce is one of the most important milestones when it comes to distributed computing, “MapReduce: Simplified Data Processing on Large Clusters”. It introduces a model for processing big data sets in parallel, so powerful that it continues to influence distributed systems almost two decades later.
The beauty of MapReduce lies in its simplicity. As many real-world data processing tasks follow a common pattern: they map a set of input key/value pairs to generate intermediate key/value pairs, then reduce those intermediate pairs to merge values associated with the same key, we hid the complexities behind two steps: map and reduce.
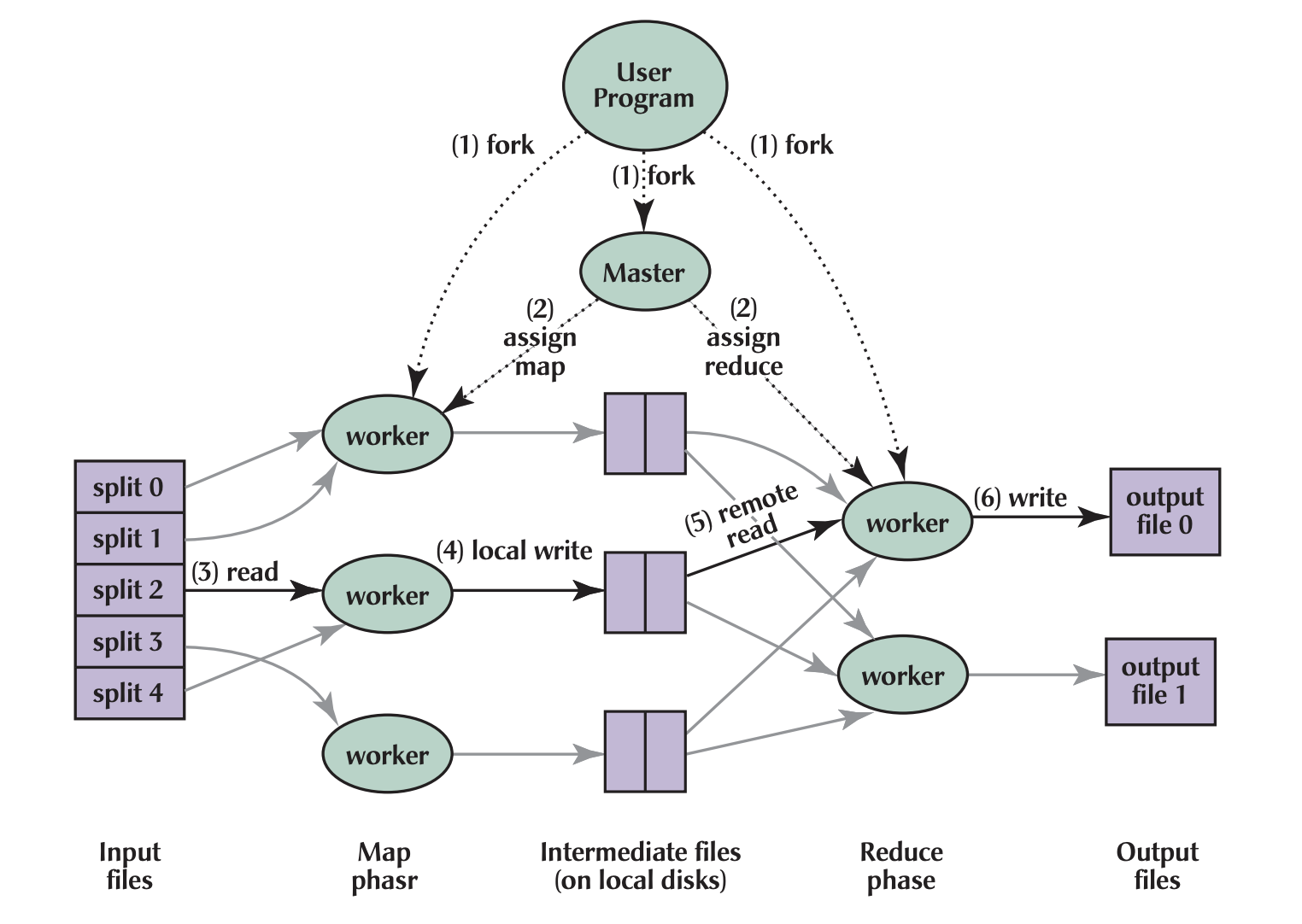
The Programming Model
To implement MapReduce, developers only need to define two prodcedures-at this point pretty obvious- map and reduce:
- Map:
(k1,v1) → list(k2,v2)- Takes an input pair and produces a set of intermediate key/value pairs
- Runs in parallel across multiple machines
- Examples: counting words, parsing log files, or extracting features from documents
- Reduce:
(k2,list(v2)) → list(v2)- Accepts an intermediate key and a set of values for that key
- Merges or aggregates these values to form a smaller set
- Examples: summing values, finding maximums, or combining partial results
Impact and usage
1. Abstraction of Complexity
MapReduce handles the messy details of:
- Partitioning input data
- Scheduling execution across machines
- Handling machine failures
- Managing inter-machine communication
This lets programmers focus on their actual computation rather than distributed systems challenges.
2. Scalability
The model scales almost linearly with additional machines. Google reported processing over 20 petabytes of data per day in 2004 - a staggering amount for that time.
3. Fault Tolerance
The paper introduced robust fault tolerance mechanisms:
- Automatic re-execution of failed tasks
- Redundant execution to handle “straggler” machines
- Checksumming to detect corrupted data
Real world use cases
The ideas in this paper spawned an entire ecosystem:
- Hadoop: The open-source implementation that brought MapReduce to the masses
- Spark: While moving beyond the strict MapReduce model, it built upon its foundations
- Big Data Revolution: MapReduce helped enable the explosion of data-intensive computing
The Legacy
While newer systems have emerged with different approaches (like Spark’s RDDs or cloud-native services), MapReduce’s influence persists in:
- The focus on data locality
- The importance of fault tolerance
- The value of simple, powerful abstractions