
Introduction
Paper review of Ryan Marcus et al. Bao: Learning to Steer Query Optimizers
Bao is an MLDB model that performs query optimization with deep reinforcment learning. It’s idea is also extended from Neo: A Learned Query Optimizer.
Reinforcement learning
Before we actually go into the model itself, we want to understand a little bit about reinforcement learning. Here, we constantly input the rewards of each action which should be the elapsed time of each query plan for each query.
We use exploration and exploitation.
- Exploitation: Choosing the best option(query plan) that is predicted at the moment
- Exploration: Giving our model some randomness to give our model room to improve and explore new options
Thompson sampling
The RL model uses Thompson sampling to sample model parameters from a conditional distribution based on experience rather than finding the most likely model with the expectation. This will enable our model to balance exploration and exploitation.
Bao system model
Bao is unique from other past MLDB models in that its training depends on the default db optimizer. 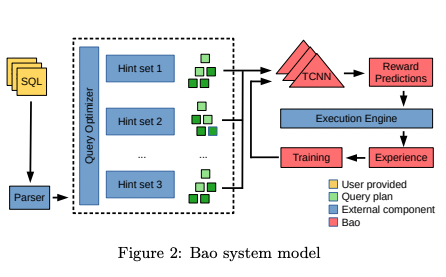
When generating execution plans for queries, DBs use hints to guide them whilst generating potential optimal plans.
Query hints
For those who are new to query optimizeres, hints may be too abstract of a description. To illustrate, a user may use “inner joins” to bring together multiple tables. Now although most would not care about the specifics of how the joins are actually implemented, DB optimizers carefully scrutinize all the information they can collect and use specific types of joins, such as index/hash joins etc.
Depending on the estimated size and cost of the operator, the specified operation may differ greatly by each different hint.
When multiple hints are joined, they form a hintset.
Back to Bao
Hence the default optimizer engine will be trained to find the optimal hintset of each query. However the required hintsets and the corresponding size and cost rely heavily on the default optimizer.
In essence, Bao can never be seperated from the underlying default optimizer.
TCNN
With the given dataset, Bao passes all the captured plans into our model which will then be fed into TCNNs - that is tree CNNs. We use CNNs because the utmost important part of estimating the best plan of queries is to capture the relations between each operators.
For example, we want to know how the query execution will be affected when the join operator comes right before the group operator(which should be denoted as the child node in binary trees).
So with CNNs, we are able to find out the spatial relations between operators and henceforth build our model.
Why not NLP or attention?
My first intuition into query optimization was, why not natural language processing? Queries are chunks of words after all, aren’t they?
To answer this question, we first need to understand that the words that consist the queries are just merely categorical data within the schemas. Also, if the table happens to change, the name means nothing, just a mere representation of each of the different columns/tables. In natural language processing, the probability and embeddings of the word relations matter. This can not be guaranteed in queries because each column/table values are independent of each other.
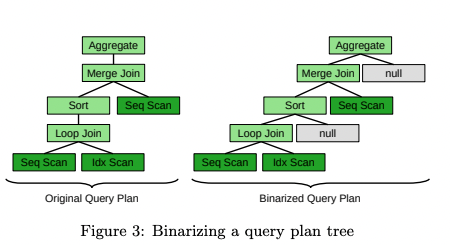
Vectorizing query plans
Now we want to flatten out our trees. To do this, we first want to one-hot encode the operator types for each node and also add the cost and size to the end of this array.
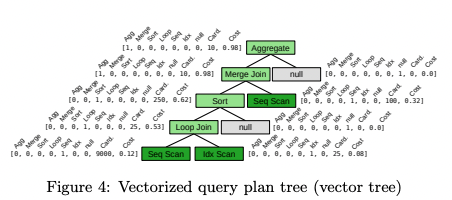
Bao model architecture
From here on, now that we’ve vectorized our tree, it’s pretty much same to the basic CNN models with convolution layers and dynamic pooling with FC layers at the end.
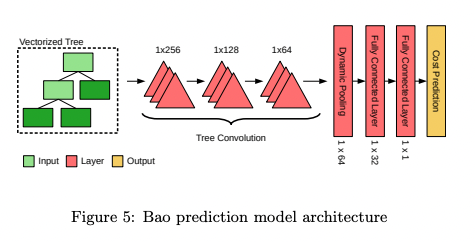
Model specifics
Some minor points to remember is that the model sets n, k each to control how many queries are run in an epoch as a batch and to limit the number of experiences that is fed into each training of the layer.