
Introduction
Paper review of Yang, Zongheng Machine Learning for Query Optimization
Boostrapping From Simulation(5.3)
Before going into real execution for fine-tuning, it enters a stage of “simulation” where Balsa inquires its basic knowledge without having to face potential disastrous plans from real execution.
Cost model for Simulator
The cost model assumes and follow the general principle that “fewer tuples lead to better blans”, henceforth minimal.
This is of course, independent of physical enumeration plans and instead uses cardinality estimates.
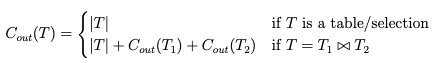
While this may cause issues of inaccuracy, it provides the simplicity and efficiency to pave way to move onto the next step of fine-tuning.
Evaluation(5.8)
But really, how do we evaluate our model? Unlike other deep-learning questions, sql optimizers don’t have a tag to pin the answer with. It way be a superior plan compared to the default optimizer but may not be the optimal one. It may be optimal but may require more resources to prepare the statements.
Do we evaluate the model with validation queries? With which metrics - difference in sum, ratios in time or percentages of queries?
Experimental Setup(5.8.1)
Use 113 JOB queries: 94 training and 19 test.
- Random Split : average situation
- Slow Split: 19 slowest queries(as test set)
TPCH: 70 training, 10 test
Experiments run against: 2 expert systems; PostgreSQL, CommDB
Environment: VM 8 cores, 64GB RAM, SSDs. NVIDIA Tesla M60 GPU
PostgreSQL: 32GB shared buffers, cache size, 4GB work memory, GEQO disabled.
Expert performance: Created primary, foreign key indexes to make baselines run JOB faster -> renders the search space more complex and challenging
PostgreSQL runtimes (train/test): JOB 115s/24s; JOB Slow 44s/98s, TPC-H 452s/49s.
Metrics: Repeat experiment 8 times and report median. But for train/test curves, wshow min/max ranges, workload runtime: sumer of per-query latencies + ratios(normalized)
Balsa Performance(5.8.2)
- What is the performance on training/test?
- How many hours to surpass expert perform. and reach peak perform.?
Figure 5.6 Median of 8 runs Table 5.2 Time taken to collect simulation data and train the model
Figure 5.7 Normalized runtime of training queries (log scale) vs. elapsed time and number of executed plans: data/sample efficiency in RL terms, as each execution is an interaction with the environment
- All executed after bootstrapping from simlation
- Balsa reaches peak after 5 hours but TPCH has fewer joins so less room for opimization(converges faster)
- Needs more plans for workloads that start with slower performance
“Therefore, experiencing more plans helps Balsa improve performance by a greater amount.”
- All non-parallel results
Analysis of Design Choices(5.8.3)
Impact of the initial simulator(5.8.3.1)
- Expert Simulator: From PostgreSQL +0.3 hours
- Balsa Simulator: aforementioned +1.4 hours
- No simulatr: initialize the agent from random weights +3.8 hours
But the simulators only make up a slight difference and eventually are caught up.
“Simulation is essential for generalization” -> Agents without simulation learning can fail at test time, high variance.
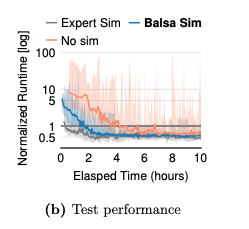
This may be due to the overfitting of the experience collected during real execution phase which is limited in quantity.
Impact of the timeout mechanism(5.8.3.2)
Timeouts: save wall-clock time on unpromising plans and learn faster(35% faster) and nudges the agents in a different direction to look for more promising plans.
Impact of exploration(5.8.3.3)
RL agents for more diverse states
- Count-based exploration: best unseen plan from beam search(top-k)
- Epsilon-greedy beam search: performance is worse(diverse plans but slower)
- No exploration
Impact of the training scheme(5.8.3.4)
- On-policy learning: Use the latest iteration’s data to update -> Don’t use the entire experience because it was already input into the data. Don’t discard our model but simply update it
- Retrain: re-initialize value model and retrain on the entire experience. Last iteration is discarded
This should be highly relevant when deciding whether to discard the model or not
On-policy saves time and the saved time is used for exploration. Better exploration thus further accelerates learning. However it has higher variance due to performing SGD on much less data. However, the slowest on-policy agent is still mostly faster than retrain agents.
Impact of planning time(5.8.3.5)
Beam Search
Comparison with Learning from Expert Demonstrations(5.8.4)
Comparison with Bao(5.8.4.1)
Differences lie in
- Balsa uses optimization that bootstraps its model from PostgreSQL’s expert plans, rather than from a random state
- Bao uses k = 2000 recent experiences which lead to highly unstable performance
Balsa outperforms because it has higher degrees of freedom
Enhancing Generalization(5.8.5)
Testing for unseen queries Balsa improves speedups on both training and test queries(JOB Slow)
- JOB: 17, 16, 6, 19 as test sets and the rest as train sets.
- Extended JOB: JOB as training set. Bao and Neo doesn’t surpass the expert but Balsa-8x(trained on 8 agents’ data) does even in iteration 0.
Behaviors Learned by Balsa(5.8.6)
Balsa learns to reduce the use of operators and shapes that incur high runtimes
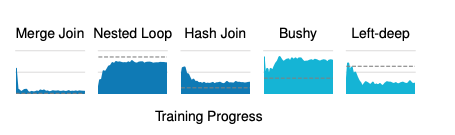
ex) Merge Joins: the use of merge joins are kept below 10% after 25 iterations.
Related Work(5.9)
Balsa is most realted to NEO(cost esimation and plan enumeration) but also uses DQ’s cost model in simulation learning. Also Balsa fine-tunes workloads in real execution.
- Expert(default) are limited in quantity and variety(only one default plan per query) vs maximal mount of experience, boosts generalization
- Addresses the challenge of disastrous and slow plans
- Novel techniques: on-policy learning, timeout, safe exploration, diversified experiences
Proposals to apply sim-to-real to learn high-quality data partitionings and applying timeouts and caching to optimize training.